Unicode in LabVIEW - How to Use Foreign Language Characters

Yannic Risters
It’s just copy and paste, right?
Some time ago, I worked on a LabVIEW application that required different language options for the UI. From a Western European perspective, the implementation of e.g. English, Dutch, and German is rather easy. You can directly type it into the text elements, like strings, captions, and labels. Or you can copy it from e.g. Google Translate and paste it into the text elements. They all use the Latin alphabet, and the “only” challenging part may be the translation (and typos).
But in this case, it was required to include languages with completely different writing systems, like Chinese, Japanese and Korean. Copy-pasting of these foreign language characters does not work:
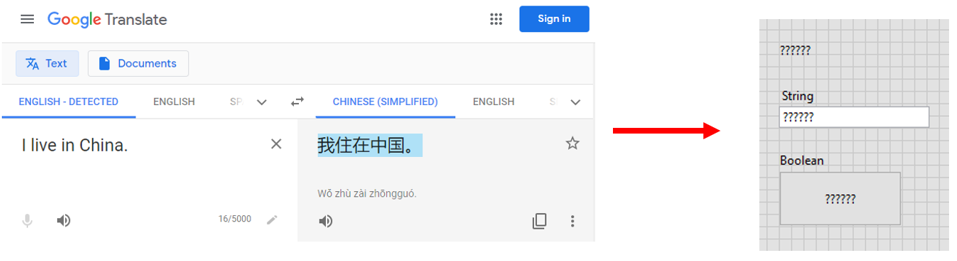
What is going on here?
By default LabVIEW (in Windows OS) uses Multibyte Character Sets (MBCS) for interpreting strings. MBCS generally supports foreign language characters. But the interpretation of MBCS is based on the regional settings of your operating system. In short, if your operating system (OS) uses the regional settings of e.g. the United States or the Netherlands, it most likely cannot properly interpret Chinese, Japanese, and Korean characters in strings.
So, what to do?
One thing you could consider is changing the regional settings of your OS. However, this can be impractical when the LabVIEW application you develop should support several languages with different writing systems. In addition, it can be quite challenging to work in an OS that was set to e.g. Japanese and you cannot read Japanese.
Another thing you could consider is asking a translator to save the requested characters as pictures, such that they could be used in picture rings. Unfortunately, this option is rather limited considering scalability.

So, is there a different approach?
Is it possible to use foreign language characters in LabVIEW without changing the regional settings of your OS or using pictures?
Yes, there is, and it is called Unicode.
Let’s talk about Unicode
Unicode is a character encoding system designed to support the interchange, processing, and displaying of written text in diverse languages. It was first released in 1993 and its core principle is to assign a unique number to every single character.
It is possible to use Unicode in LabVIEW. However, it’s necessary to first tell LabVIEW that it should use Unicode. This means that the entry “UseUnicode=TRUE” needs to be added to the LabVIEW configuration file “LabVIEW.ini”. Do not forget to restart LabVIEW, when it was already opened.
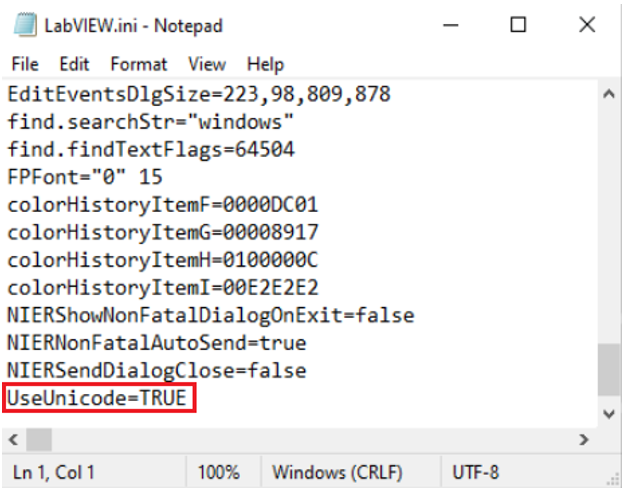
Afterwards, you are ready to manually copy foreign characters from e.g. Google Translate and paste them into LabVIEW. This works for string constants and controls, Boolean texts, captions, and (free) labels.
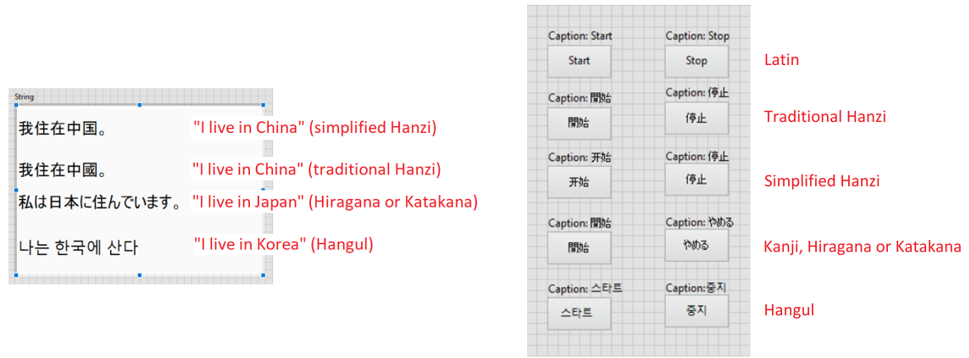

It’s also possible to programmatically set foreign language characters, e.g. from a string constant to a string indicator.
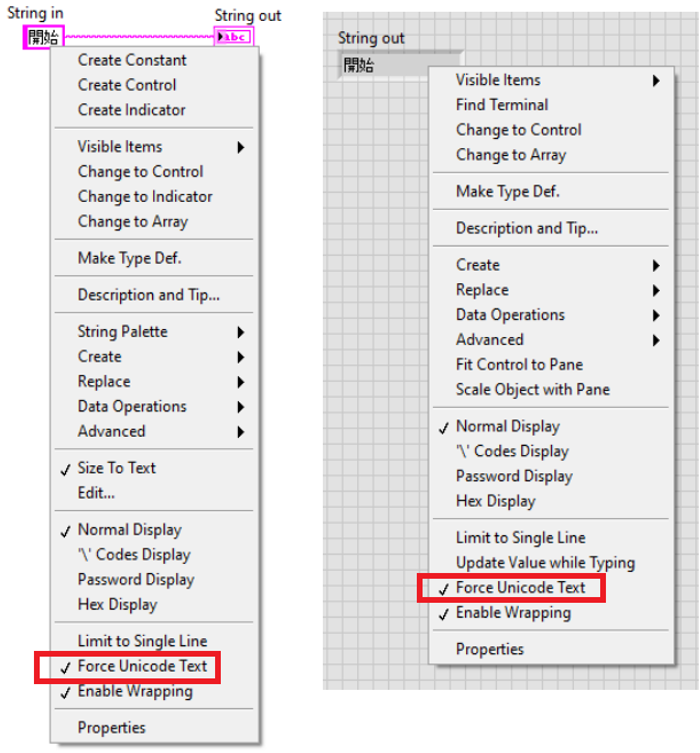
However, do not forget to enable the “Force Unicode Text” for all constants, controls, and indicators that should use foreign language characters (in this example, both the string constant and indicator). Otherwise, you will get some funny stuff like:

It‘s also possible to programmatically set foreign characters as e.g. Boolean text. However, it is necessary to enable the “Interpret As Unicode” property for Boolean texts. This property is private and is only available in LabVIEW after adding the entry “SuperSecretPrivateSpecialStuff=TRUE” to the LabVIEW.ini file.
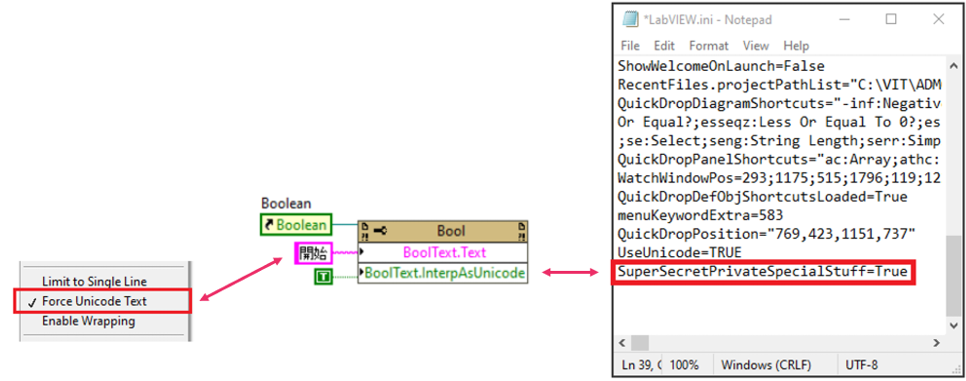
Is Unicode the most optimal solution?
At first glance, the application of Unicode in LabVIEW seems to be the optimal solution for using foreign language characters. Unfortunately, it is not that simple, and this is related to a very large DISCLAIMER:
Unicode is officially NOT supported by the LabVIEW environment. There is only limited support for Unicode strings in Windows OS, and it was NOT fully tested for both the development and run-time environment. LabVIEW versions older than LabVIEW 8.6 do not include all features of the already limited support.
What are the consequences?
1) Unicode does not work for all text elements
As previously shown, Unicode and thus foreign language characters can be applied to the following text elements:
• Captions of controls and indicators
• Boolean texts
• (Free) Labels
On the contrary, Unicode does not work for labels of constants, controls, and indicators; and VI descriptions. For example, if you try to manually copy and paste foreign language characters into them, no text will appear.
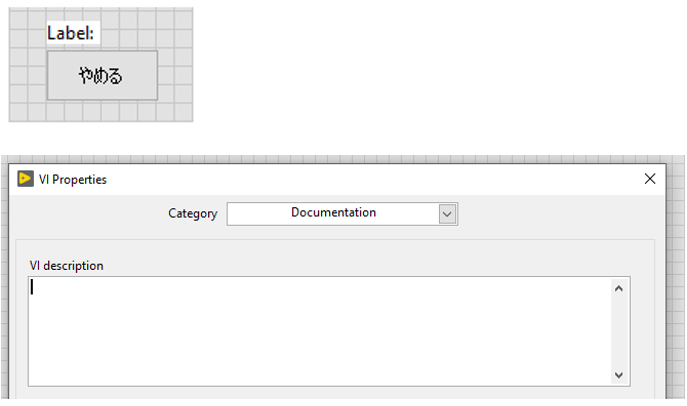
2) Unicode is unstable and vulnerable to bugs
After working some time with Unicode in LabVIEW, you will realize that strange bugs appear and that it is not very clear why. Here are a few bugs that I encountered:
• Text that was written before enabling Unicode may not be correctly displayed anymore.
• Text may be strangely displayed although it was written after Unicode was enabled.
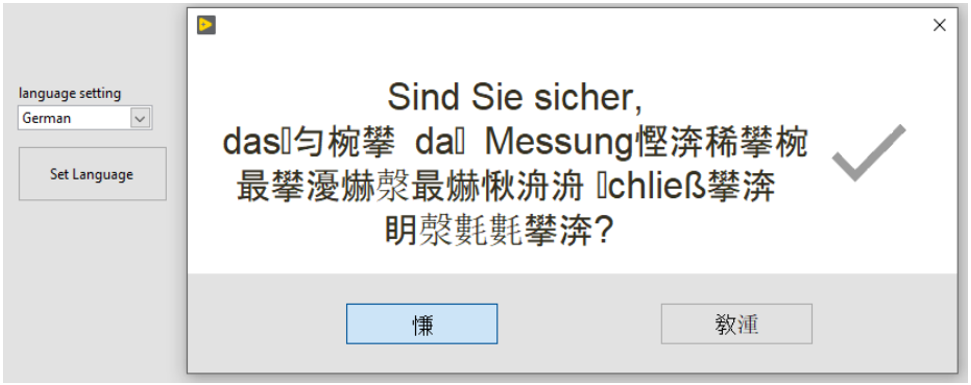
• Text may change strangely while editing, like resizing the text element:

What about LabVIEW on Linux OS?
Up to this point, I assumed that most LabVIEW developers work in Windows OS. But suppose that you use LabVIEW on Linux. How is the situation considering Unicode and using foreign characters?
Unfortunately, it has to be concluded that Unicode is completely unsupported in any Linux version of LabVIEW. Adding “UseUnicode=TRUE” to the LabVIEW configuration file does NOT enable Unicode. Thus, setting foreign language characters manually or programmatically does not work. It will also not work if you try to migrate a VI including these characters from Windows to Linux.
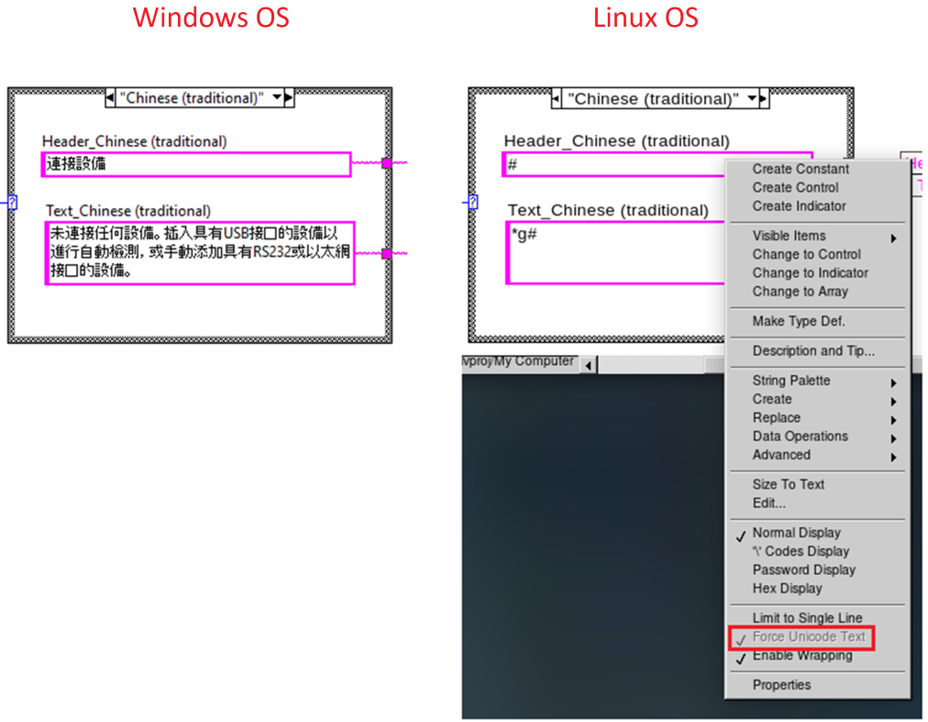
What about LabVIEW in Mac OS?
So, you’re a Mac user? How does it look on Mac OS?
You’re the lucky one, actually! Copy-pasting simply works. There is no need for enabling Unicode in the LabVIEW configuration file, which makes it more straightforward to use on Mac OS. So far, I also did not encounter any bugs here, which gives the impression that it is much more stable than compared to Windows.
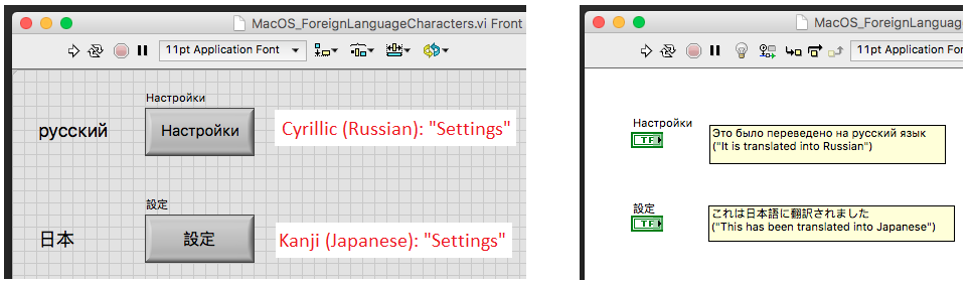
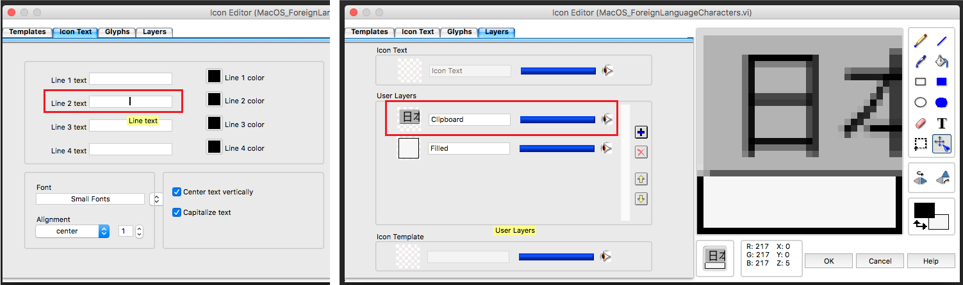
The only drawback here is maybe that using foreign language characters only partially works for VI icons. If you try that, these characters are inserted as an image and not as text.
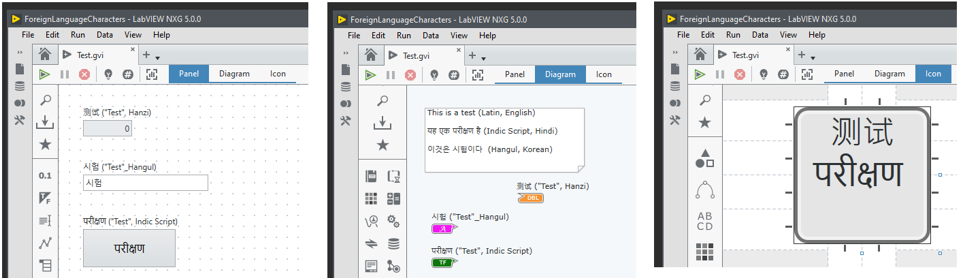
What about LabVIEW NXG?
You may already know that NI stopped further developing and supporting LabVIEW NXG. So, why even bother to a look at it?
Well, LabVIEW NXG is also used in the LabVIEW NXG Web Module so it may be interesting to know that the string data type was updated such that it supports Unicode. This means that using Unicode for applying foreign language characters simply works, even for VI icons.
In conclusion:
It is a tricky task to include languages with different writing systems in your LabVIEW application, and there is not really one solution.
If you need to develop an application for a specific language, and you are capable of reading it, you may consider changing the language settings of your Windows OS. If it is not required to take into account scalability, and you need to include several languages, it may be the simplest solution to use pictures and e.g. picture rings. However, if scalability needs to be taken into account, this is not really an option. In that case, it may be necessary to use Unicode. You will then encounter the least difficulties or no difficulties at all when using LabVIEW on Mac OS or the LabVIEW NXG Web Module.

